Appearance
RPA 元素的高级使用
目录
高级拾取-相似元素拾取
相似元素拾取是处理重复结构界面的强大功能,可以让你一次性操作多个相似的元素。
什么是相似元素
相似元素是指界面中具有相同或相似结构的多个元素,例如:
- 列表中的多个项目
- 表格中的多行数据
- 表单中的多个输入框
- 菜单中的多个选项
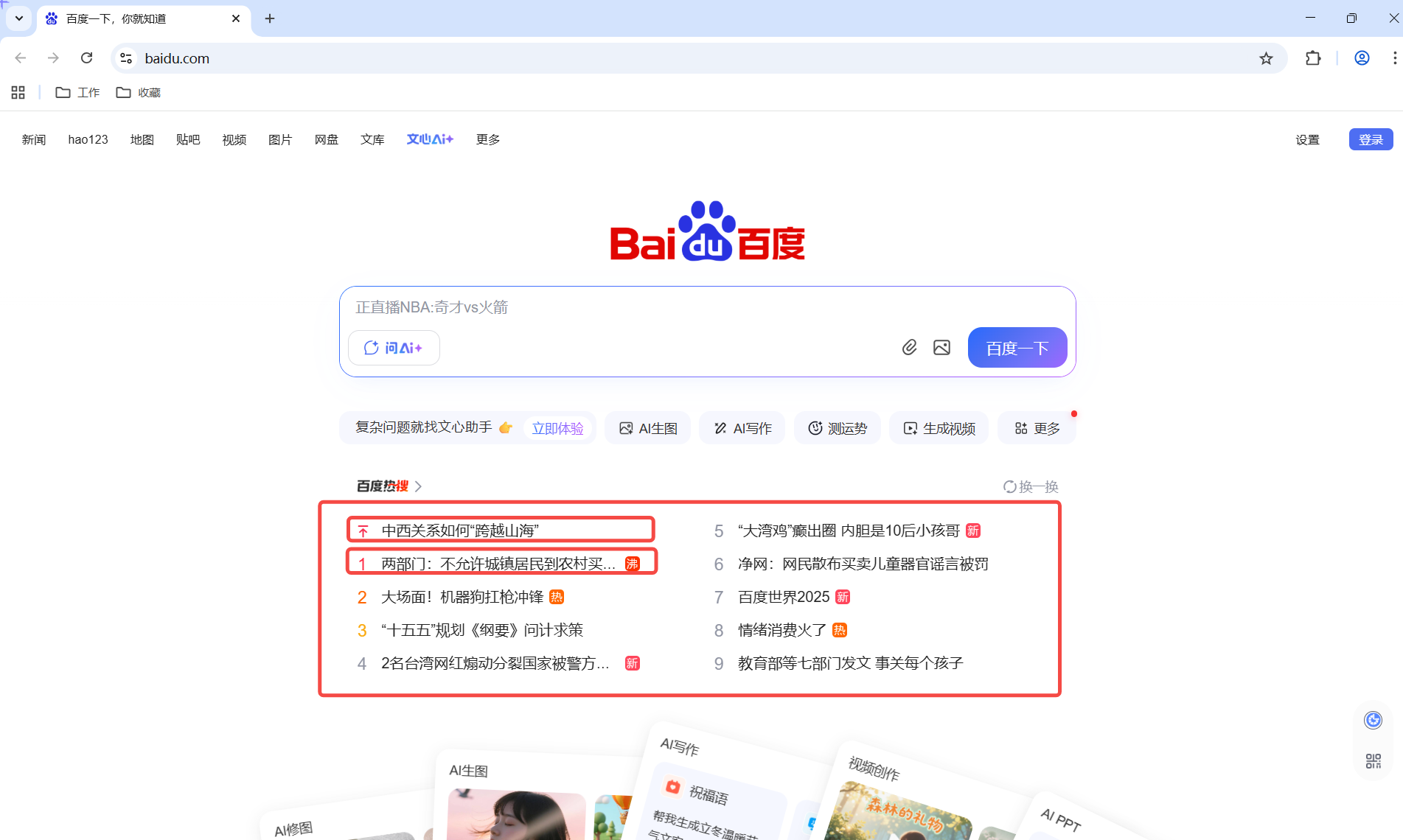
举个例子:
百度热搜就是一个列表
如何使用相似元素拾取
基本步骤:
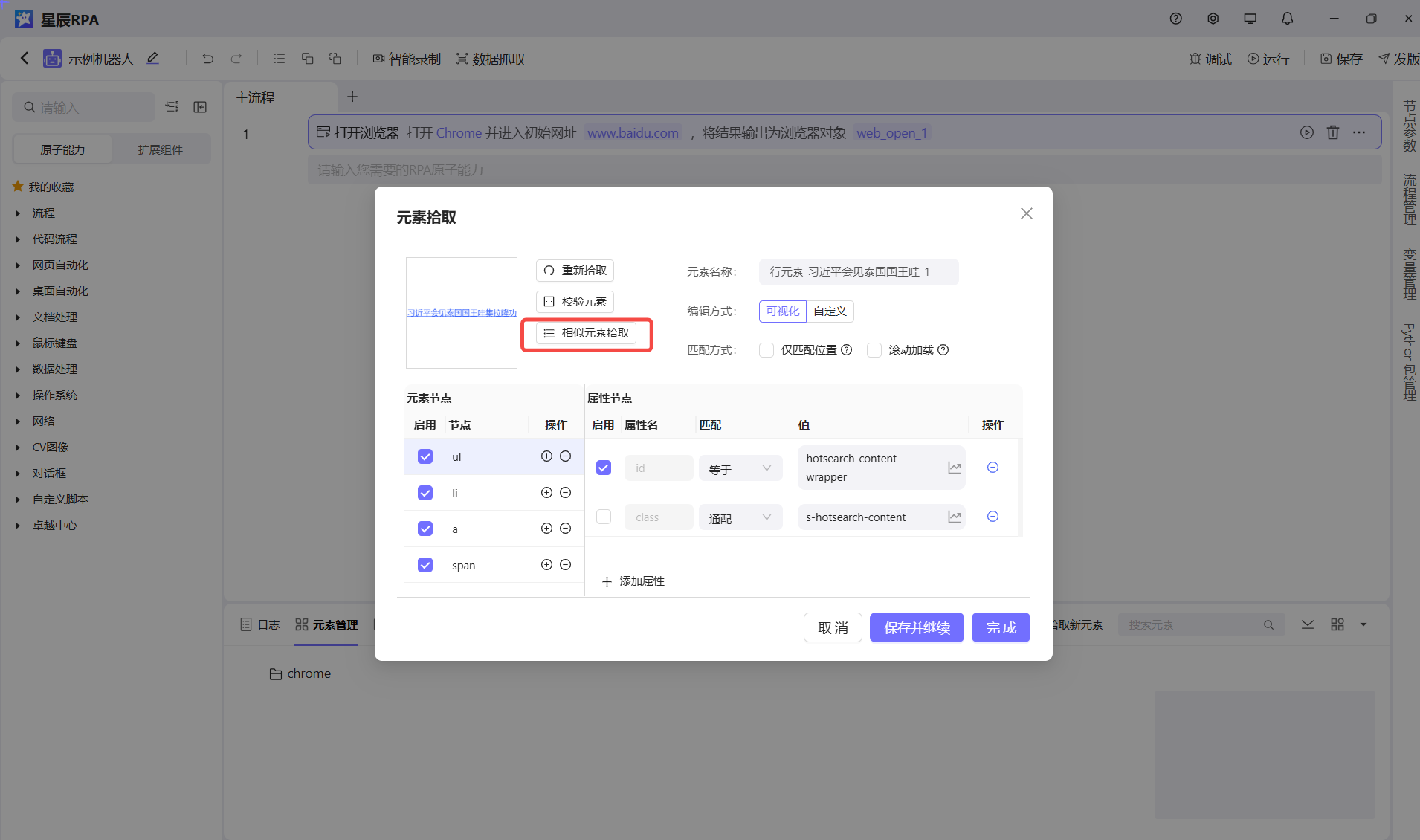
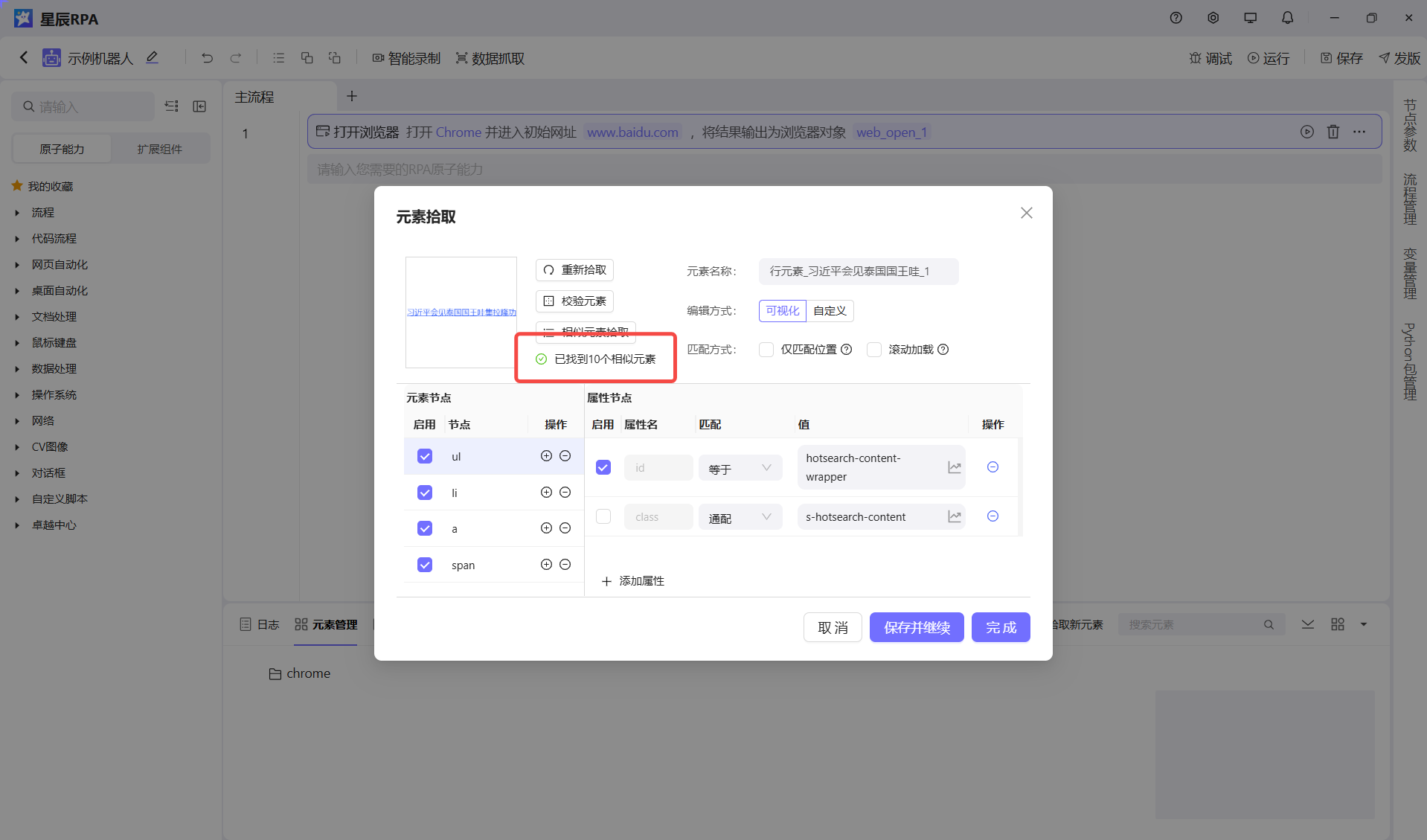
先拾取第一个元素,不要立即点击完成,点击相识元素拾取,再次拾取第二个元素,两次拾取后,程序自动比较两个元素的公共父级,获取子元素
使用场景示例
场景 1:批量获取文本内容
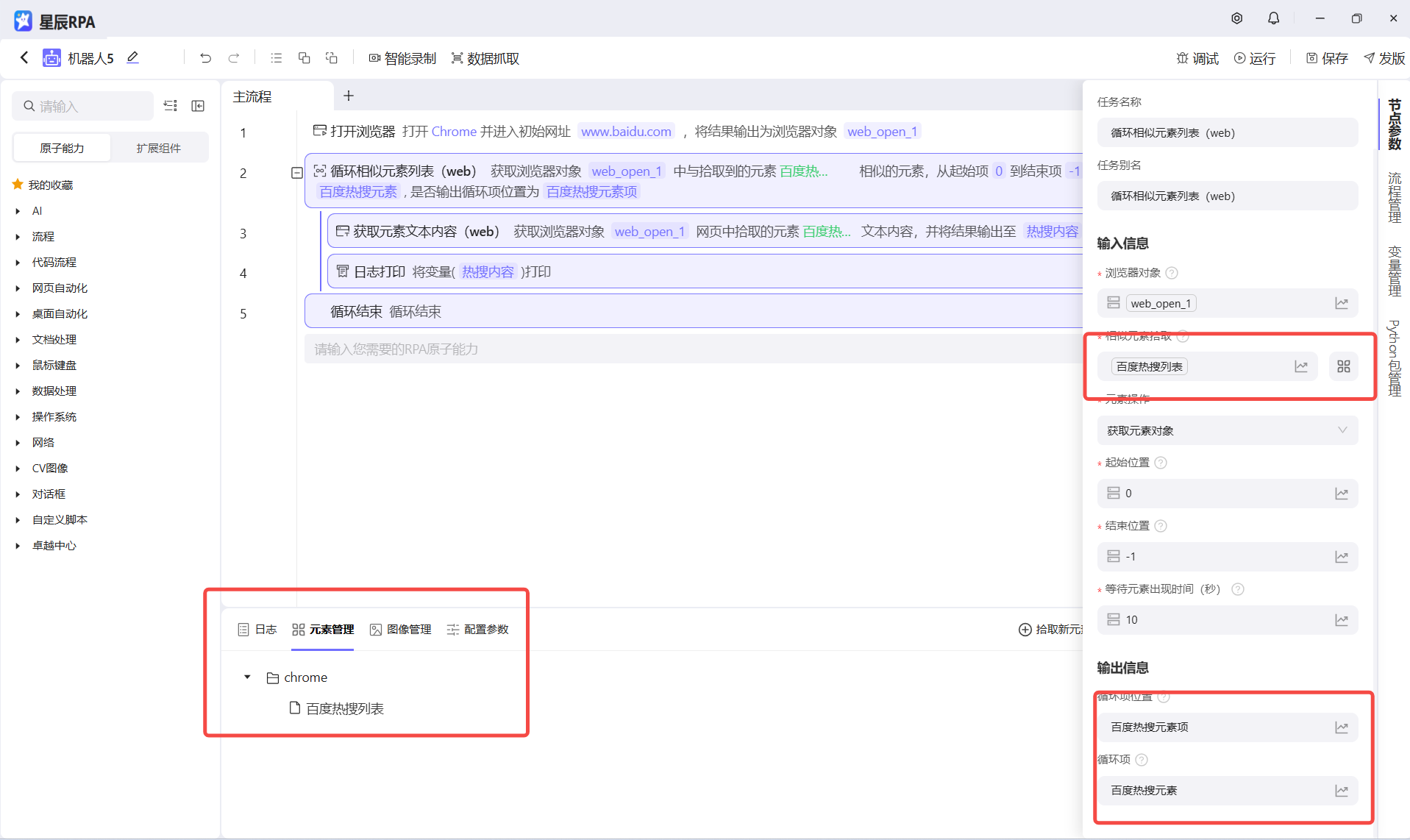
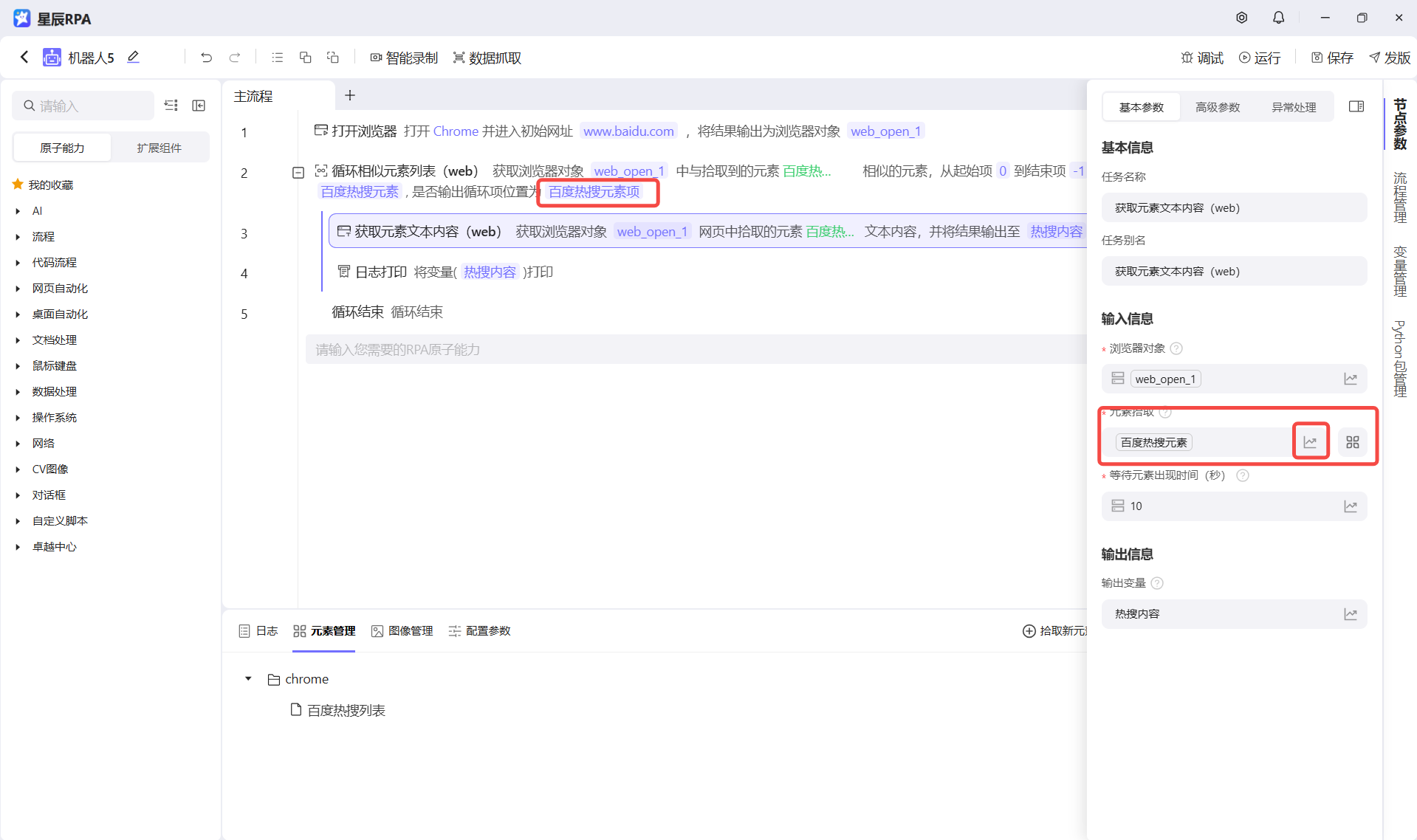
我们通过循环相识元素列表来遍历这个相识元素,也就是百度热搜列表,然后在循环项中通过获取元素文本的内容去获取每一项的值
注意 !!!:
- 这个循环相识元素列表类似代码的For循环
- 获取元素文本的内容,这个原子能力的元素要接受循环出来的项,也就是元素对象
高级拾取-批量元素拾取
这里不做详细解释,请关注批量元素拾取专题
web元素编辑-高级
在拾取元素后,自动策略会给元素生成一些属性标记,对于普通元素来说,无需修改元素节点,元素属性,但是对于一个动态元素,iframe内嵌,shadowRoot 元素可能需要进行二次修改已达到更准确的定位。
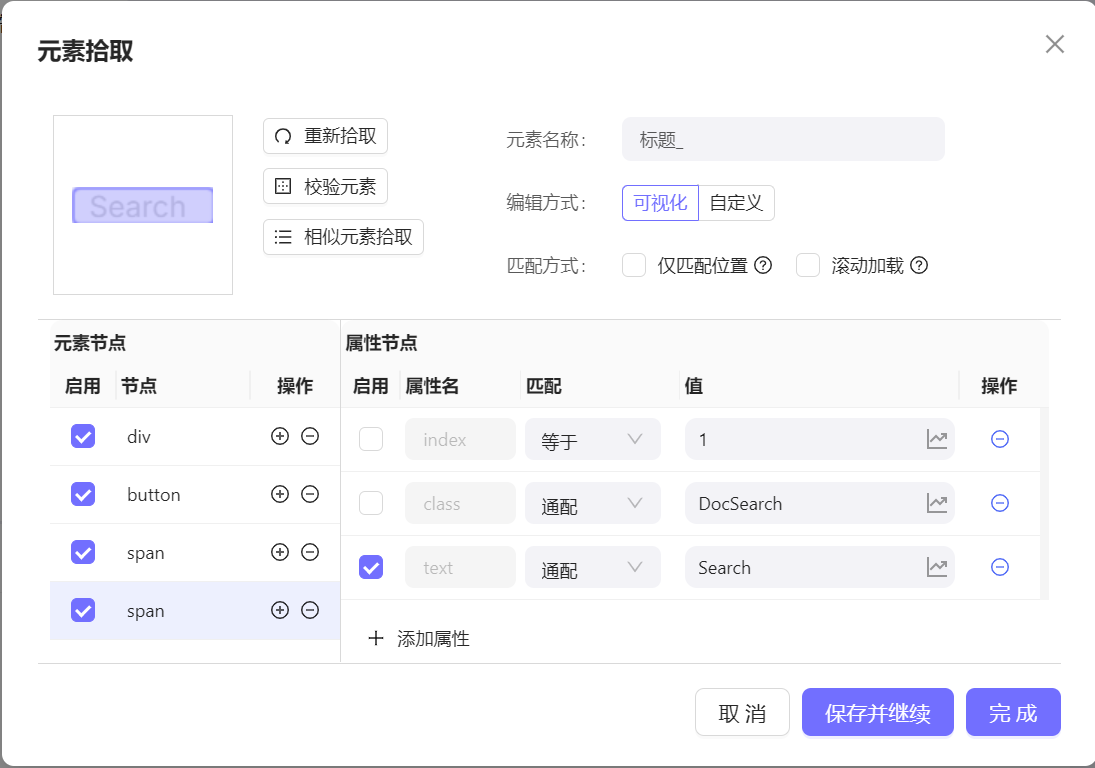
- 仅匹配位置即该元素的节点属性存在
index的属性都会在运行时启用有效,常用于有翻页场景的定位,例如:翻页获取每一页的第一条元素 - 滚动加载则是在获取不到元素时,尝试滚动整个窗口的页面,以达到加载更多数据的场景,最多滚动20次。例如:获取京东首页商品瀑布流中首次加载不存在的元素,例如第100个商品。或者在查找商品评论时,滚动加载。开启滚动加载运行时间将变长,可能会导致运行超时。
可视化编辑元素
按节点的属性结构展示
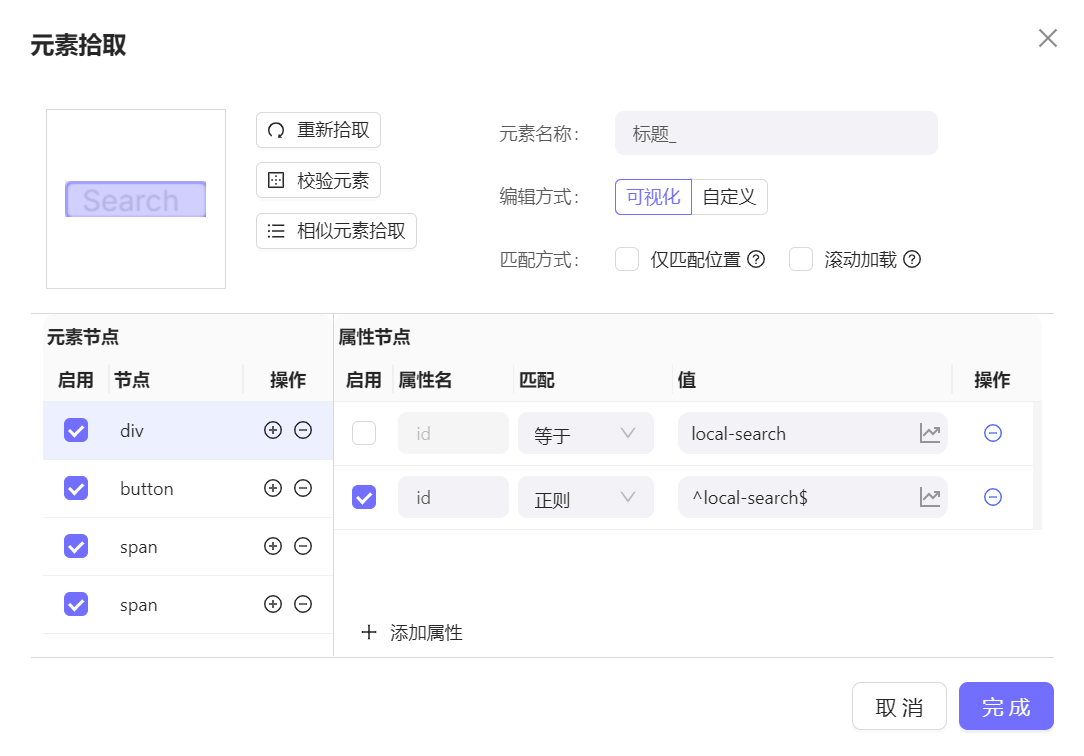
index: 节点在父节点的索引,仅在节点存在同名兄弟节点时存在class: 节点的 class 类名,会优先取兄弟节点中唯一的,特殊的,部分可能是动态class 不会取值type: input节点的类型,例如,text, button, radio, checkbox等,主要是用于输入元素的区分text: 目标节点,也就是最后一个节点的 nodeText, 常用于文本定位,按钮定位,即该文本基本固定不变,例如翻页按钮 "下一页" 这种情况节点默认都会启用,属性会在自动策略下勾选,也可手动更改勾选状态。
节点,节点属性可以添加删除。
属性匹配规则有等于,通配,以及正则三种,通配即包含,意思就是该节点属性包含属性值,正则即该节点属性符合该正则关系, 例如以下规则也可实现定位
元素属性值支持全局变量
自定义编辑元素
按元素的部分属性展示
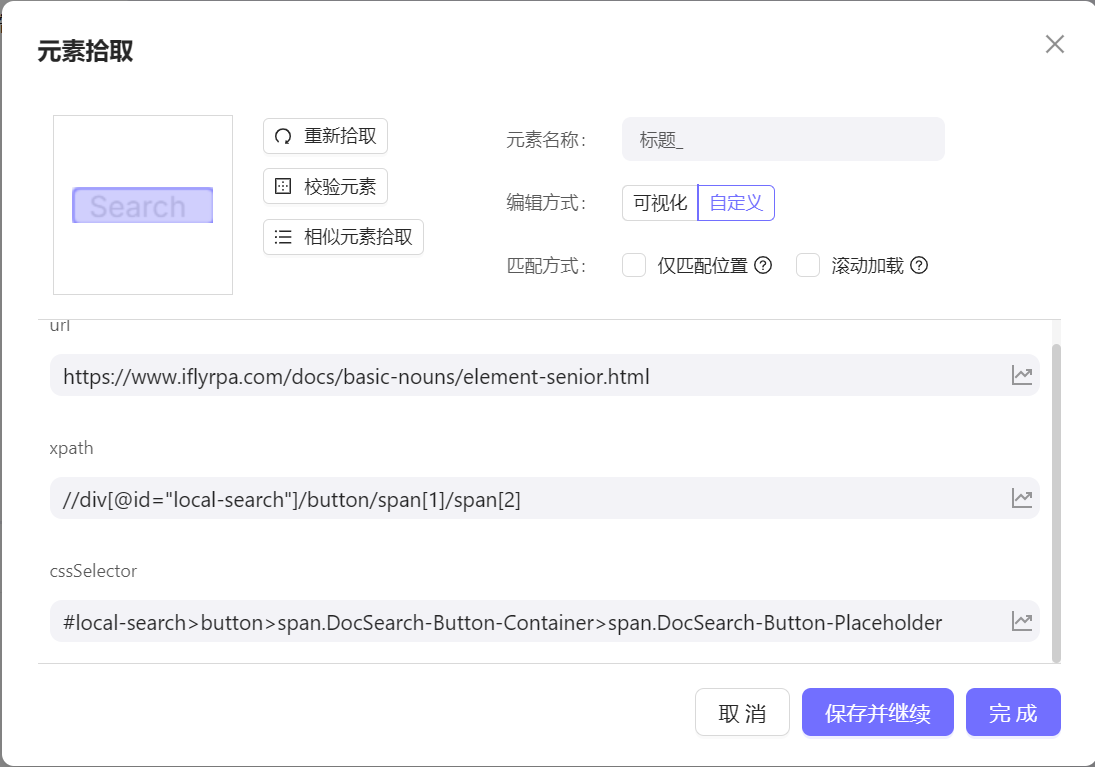
url 元素存在的页面地址
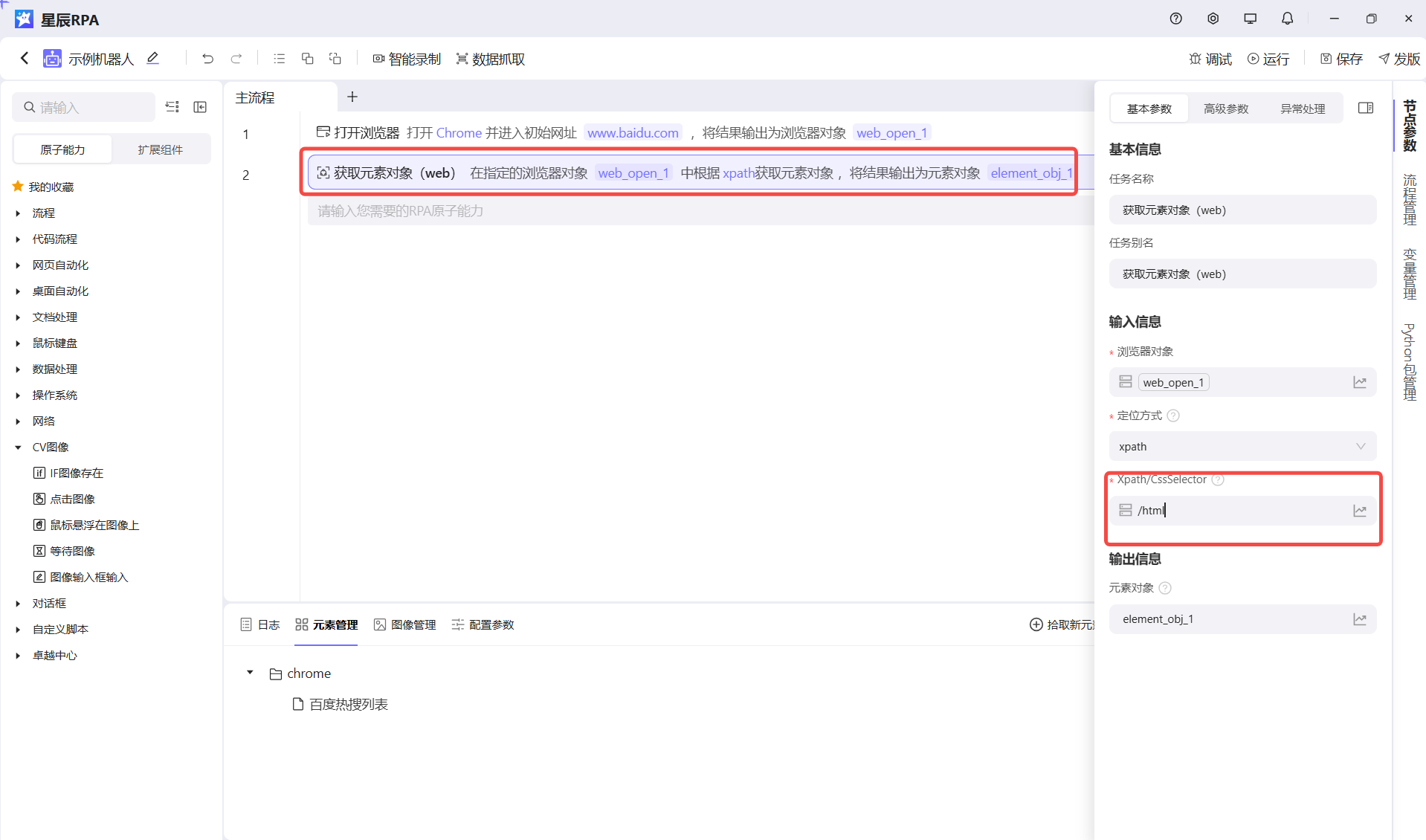
xpath 元素的xpath
cssSelector 元素的css 选择器, 在元素为shadowRoot 元素时,仅支持cssSelector 的方式定位,每一层以
$shadow$分割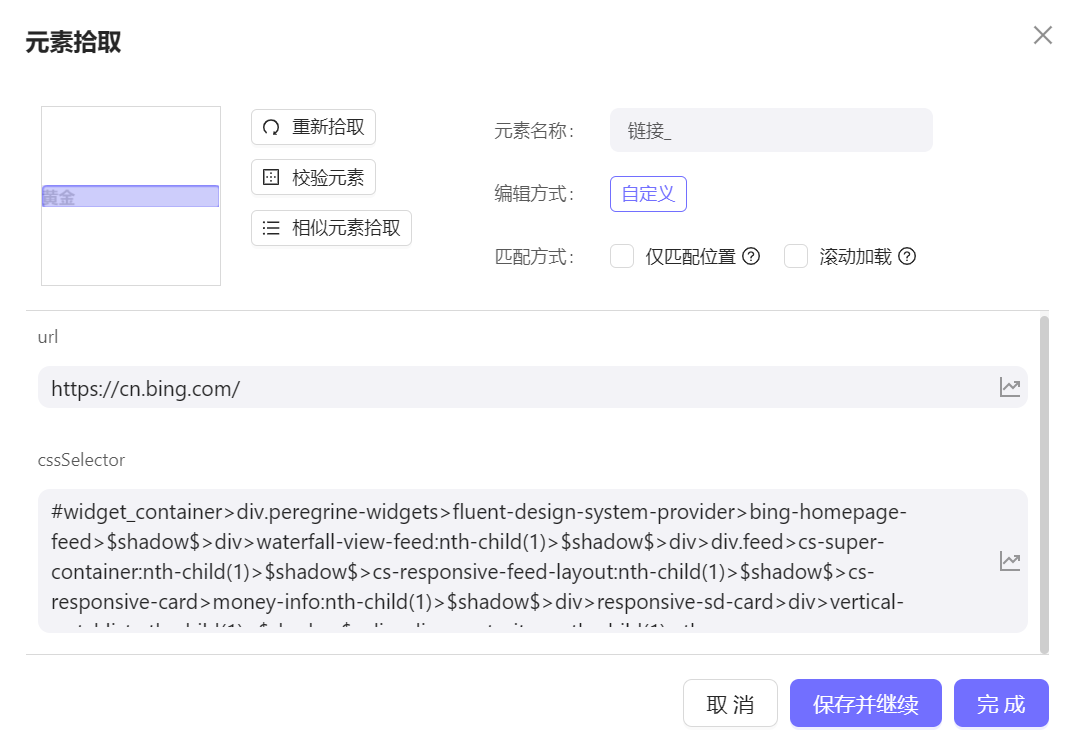
iframeXpath 仅在iframe 嵌套的元素时存在,辅助元素唯一定位, 必要时可以修改帮助iframe 动态元素定位,支持嵌套,以
$iframe$分割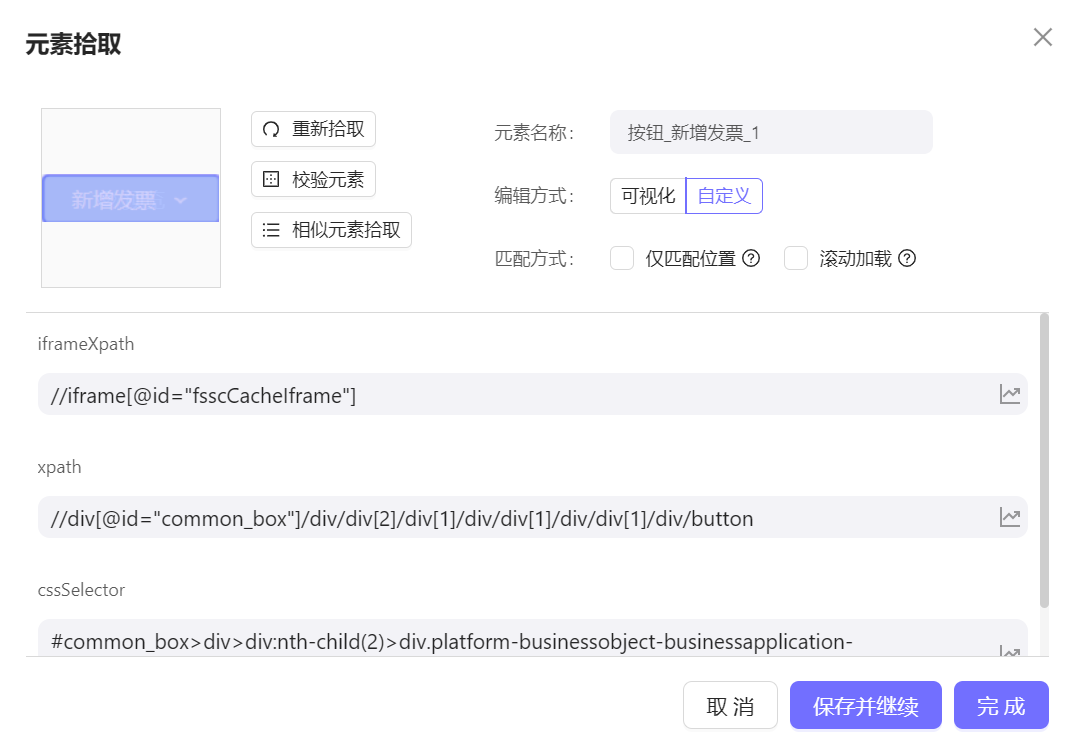
复杂场景处理
在实际使用中,可能会遇到一些复杂的场景,需要特殊处理。
场景 1:动态内容
问题:元素是动态生成的,每次加载时可能不同
- 首先这类问题很麻烦,由于依赖于第三方软件实现,但是第三方软件不受我们控制,目前的解决方式还是先分析他们的变动范围做调整
- 不过虽然困难重重,但是我们还是有一些方式方法来尽量减少由于第三方软件的动态改变而影响到我们拾取的准确度
解决方法:
方法一:使用相对元素
当目标元素本身不稳定,但其周围的某个元素(锚点元素)比较稳定时,可以使用相对元素定位。
演示:
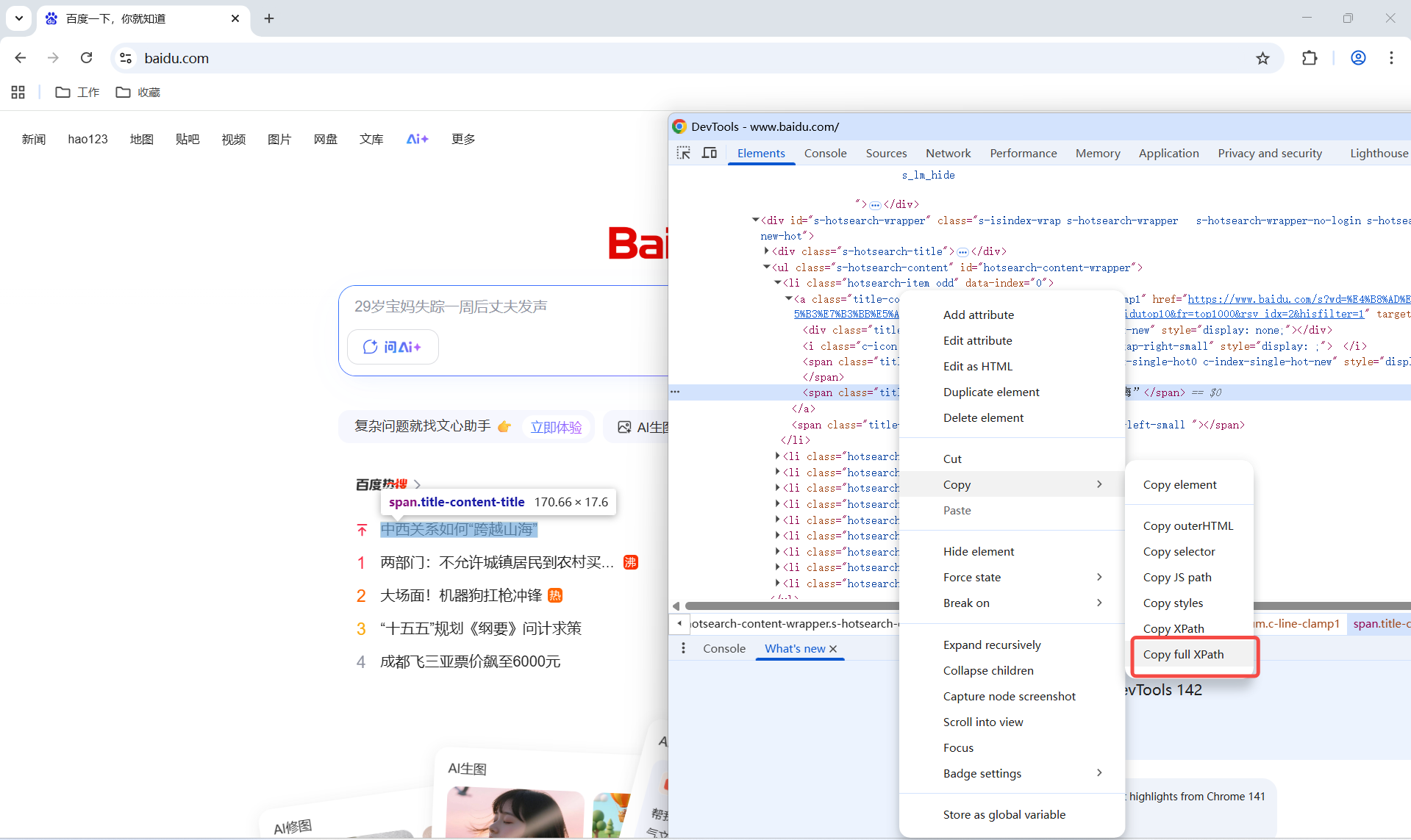
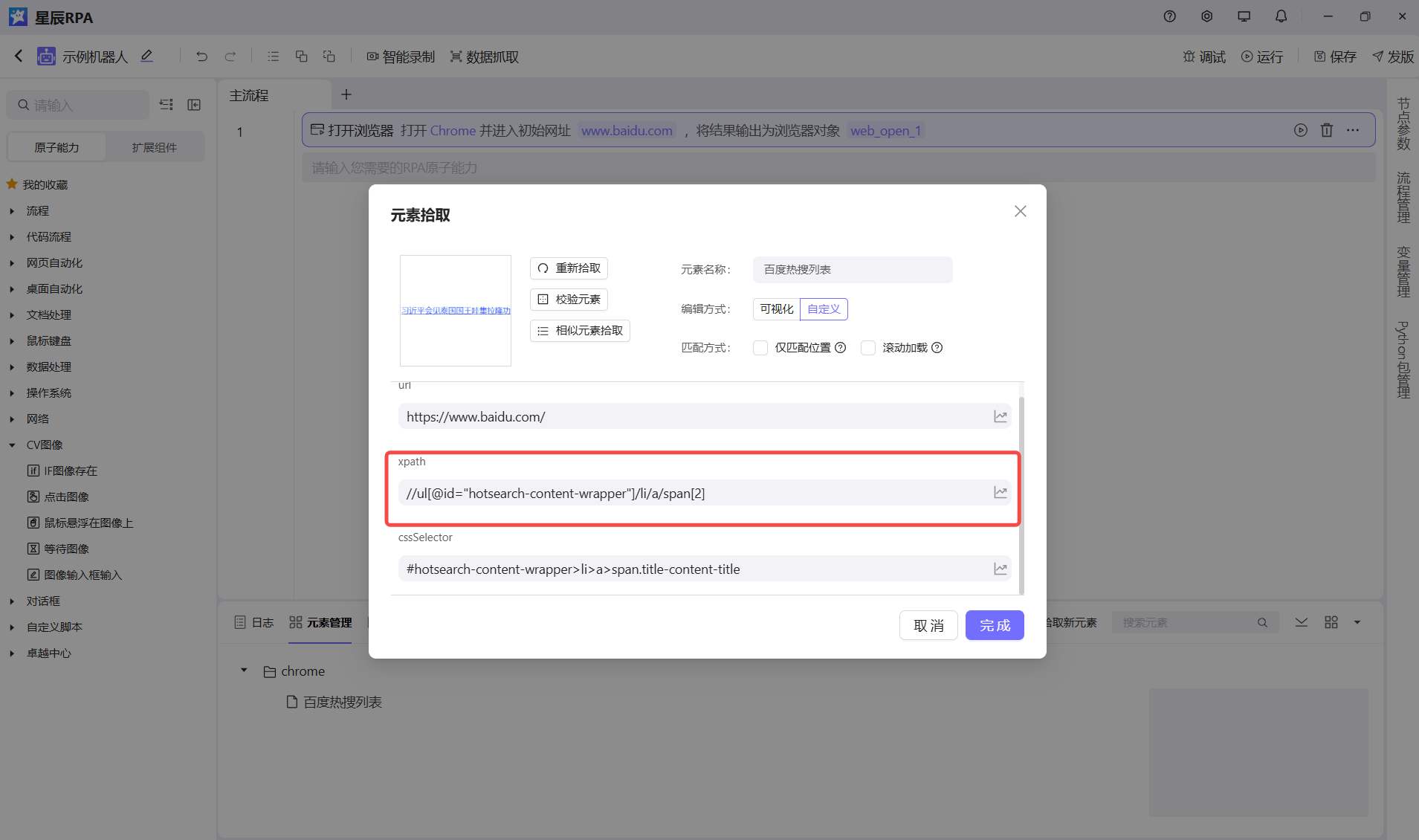
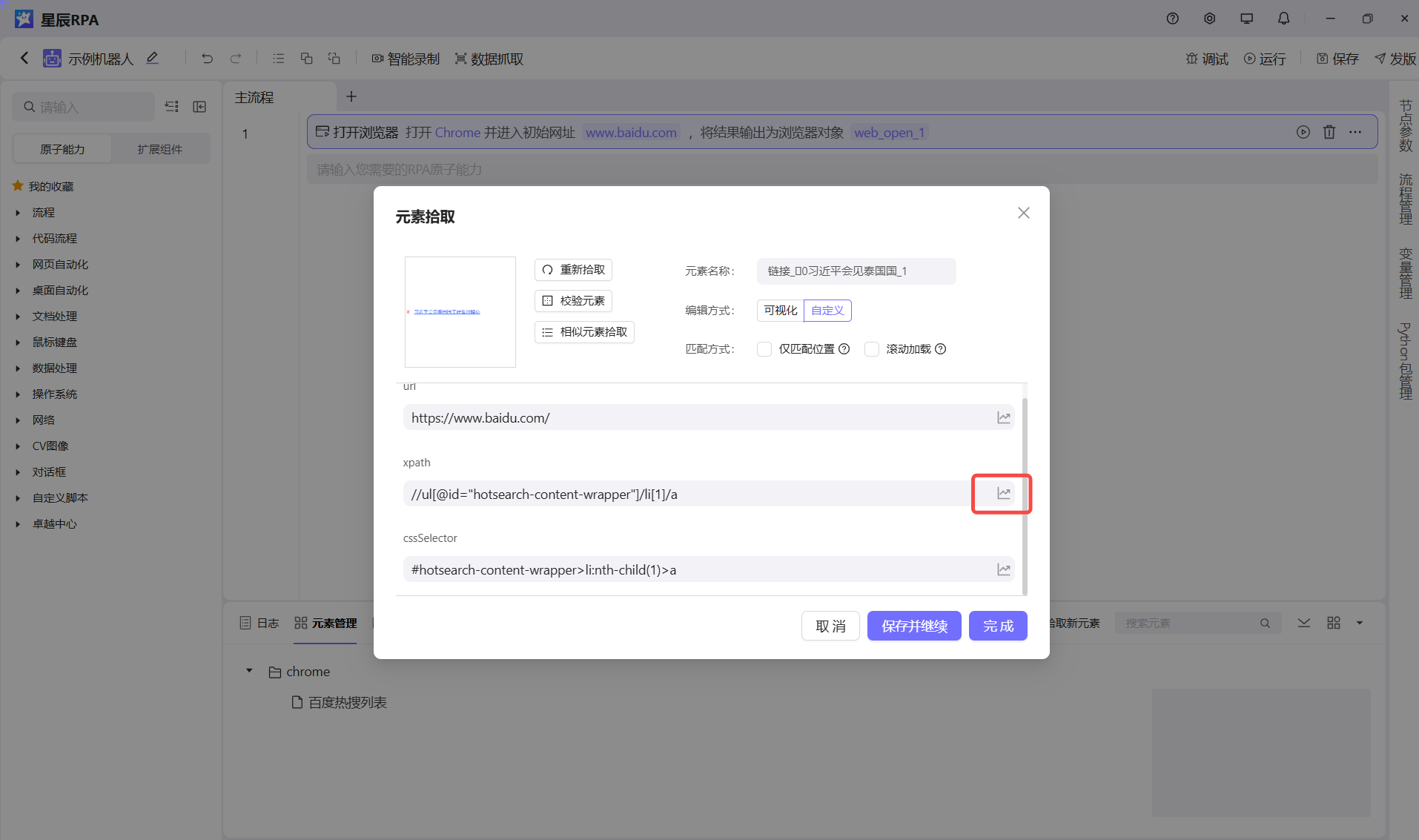
这里拿web举例,如果我们用分析工具分析元素, 我们拿到的是这个
/html/body/div[1]/div[2]/div[3]/div/div/div[5]/ul/li[1]/a/span[2]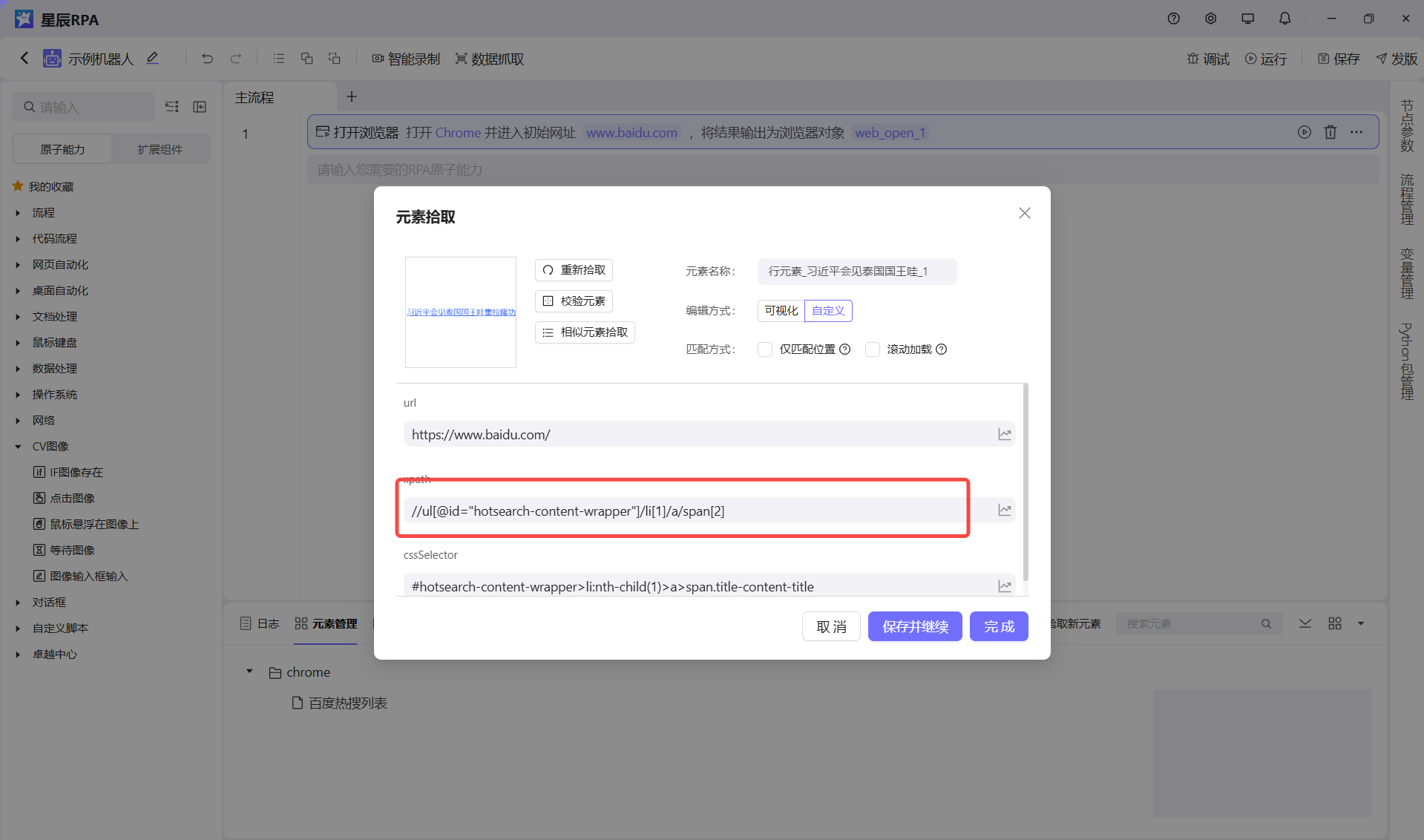
但是用我们的拾取去获取的话,我们选择相对的,这样尽量减少变动产生的影响
//ul[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]注意!!!:不过可惜的是,web页面对这块支持的比较好,但是桌面元素由于平台属性对这一块支持的并不够好
方法二:分析变动,剔除xpath部分属性
当元素的xpath路径中包含不稳定的属性时,可以通过编辑元素来剔除这些不稳定的部分。
演示:
还是拿刚刚的举例,假如我们第一次获取的数据如下
//ul[@id="hotsearch-content-wrapper"]/li[1]/a/span[5]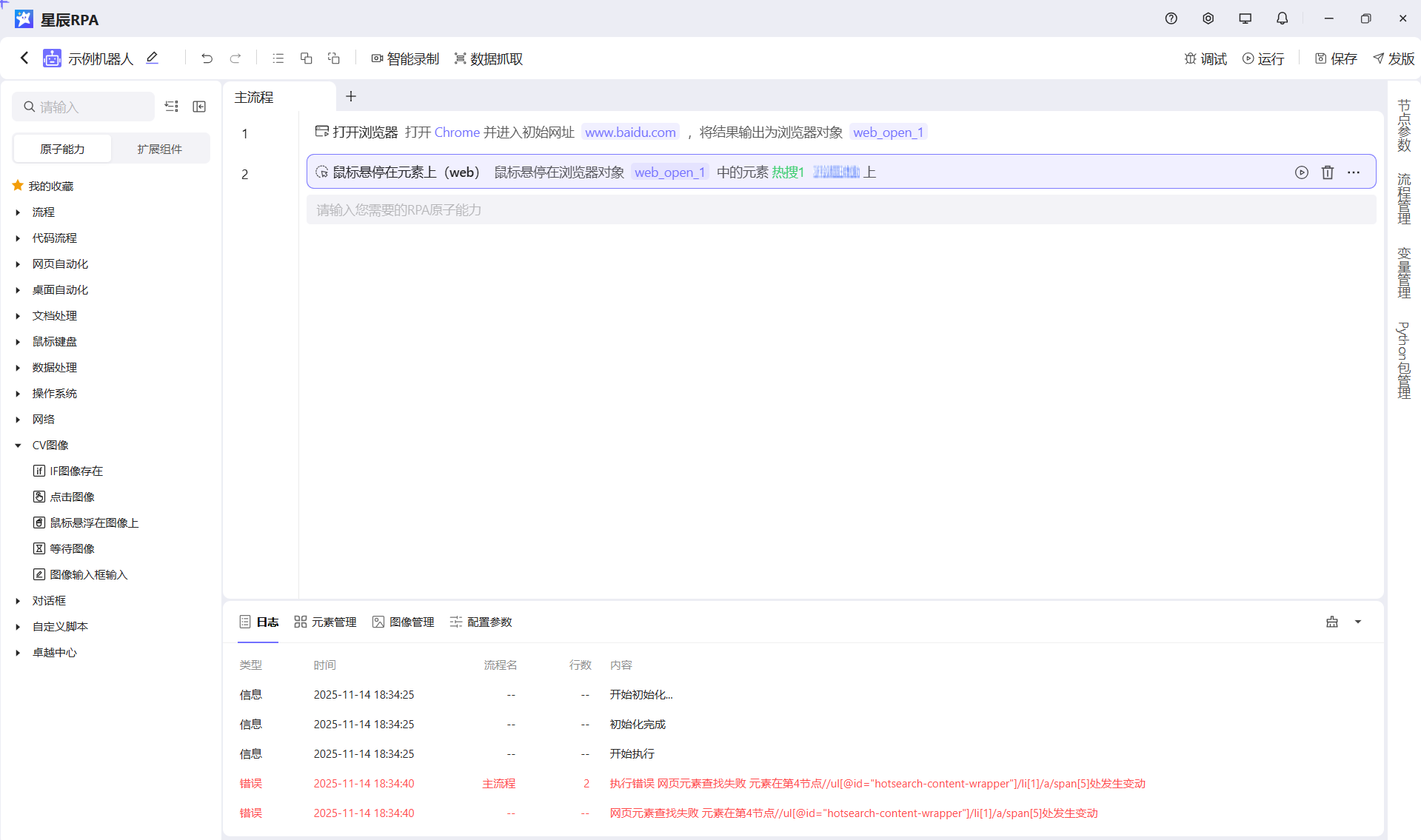
第二次获取数据发生了改变,第二次应该如下
//ul[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]我们可以看到其实就是 span[5] 后面的这个值在不同时刻这个是不稳定的,我们可以尝试剔除这个添加其他的标记来处理
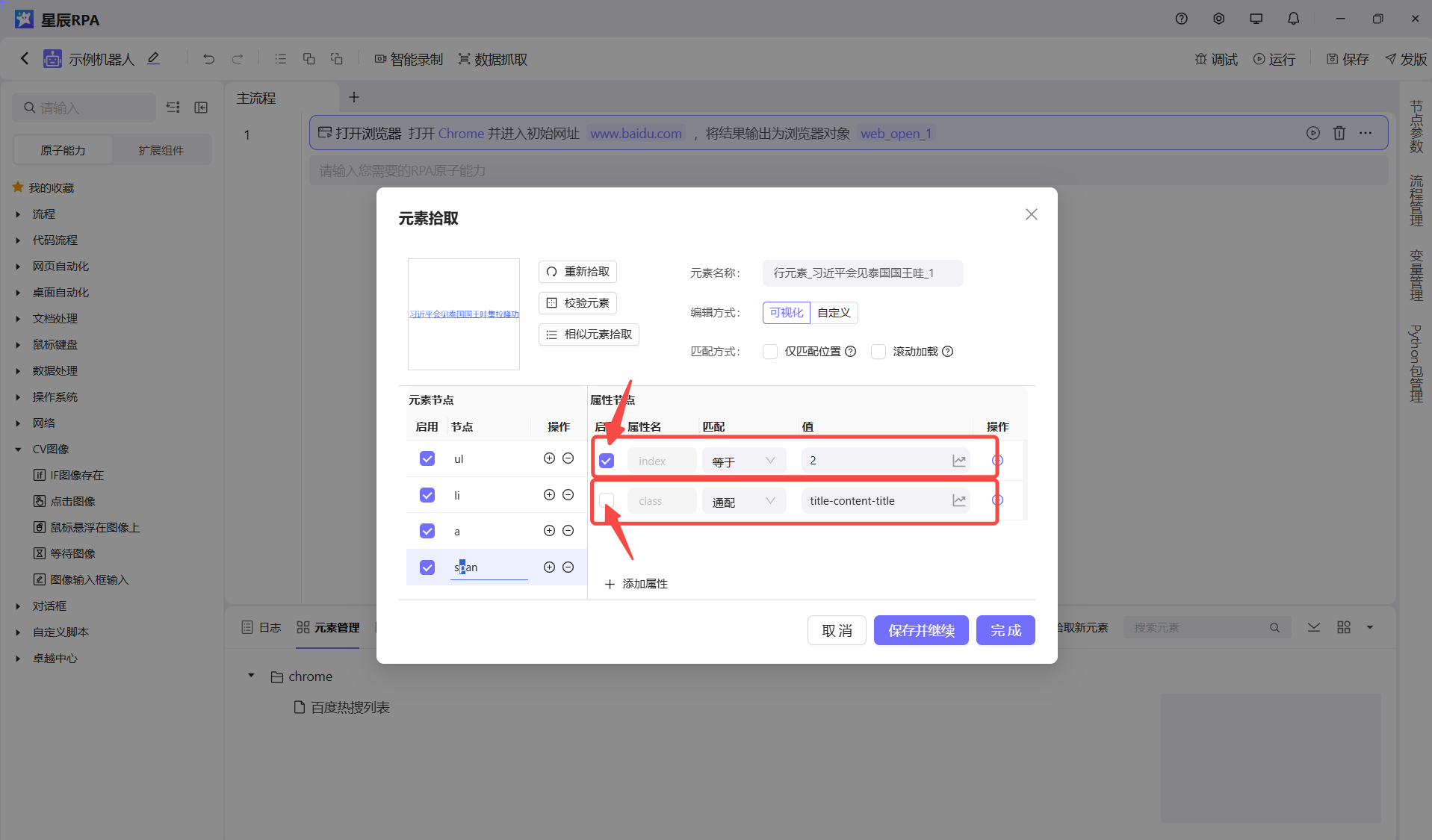
一句话,哪里经常变动,那些就不勾选,那个不经常变动,就勾选上,我这里只是一个例子,如果选择那个属性也涉及到较多的分析案例和第三方的实现,这一点我们只能提供相应的工具来减少这些变动
注意:
- Web是通过开发者模式的来做辅助分析,或者更高级的可以直接使用xpath
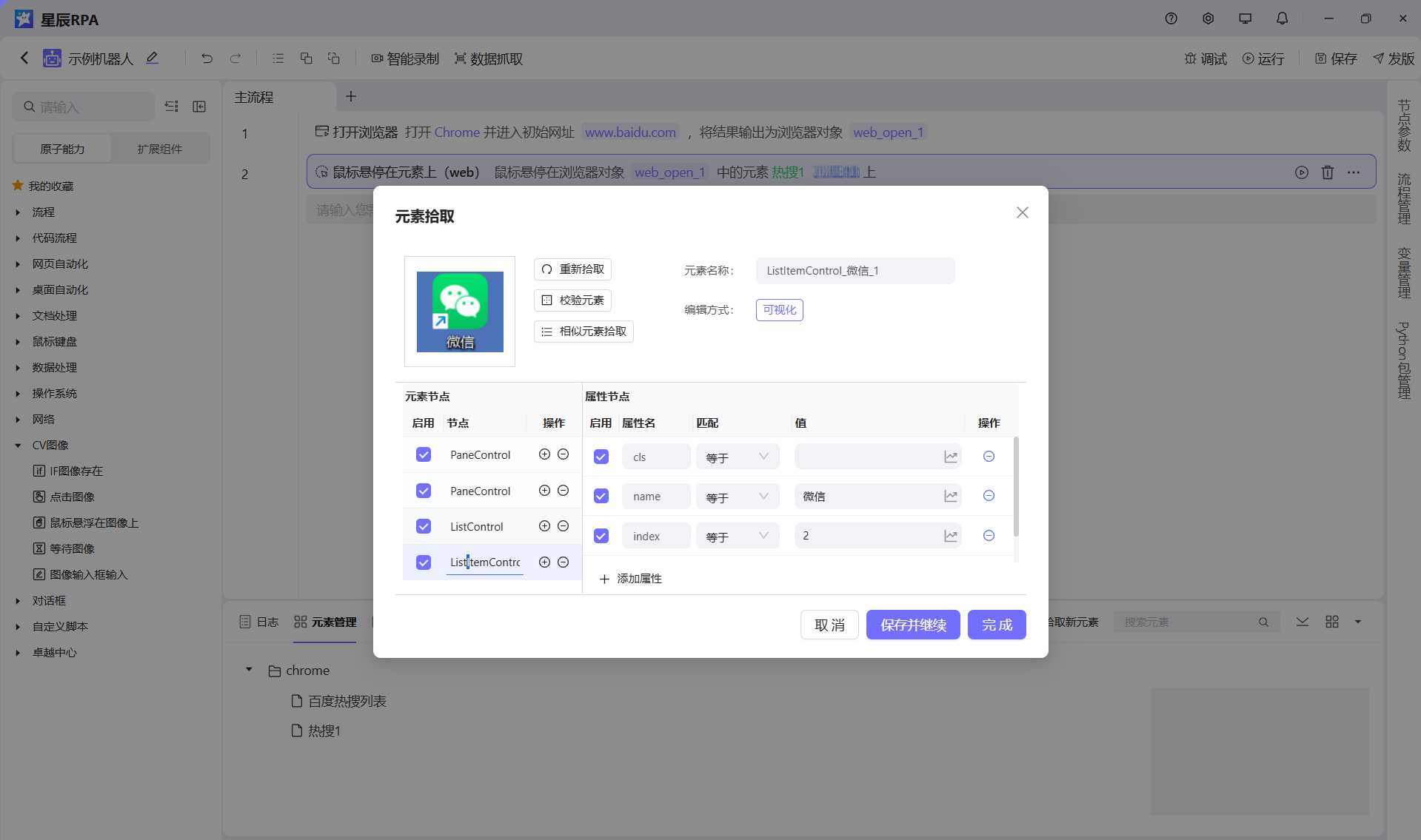
- 而桌面的话可以使用 inspect.exe 来进行分析,分析过程类似Web我就不在赘述,考虑到桌面元素的变动不会这么频繁,理论上是不会出现经常变动的问题,不过越来越多的web套壳应用越来越多,这个挑战越来越加剧
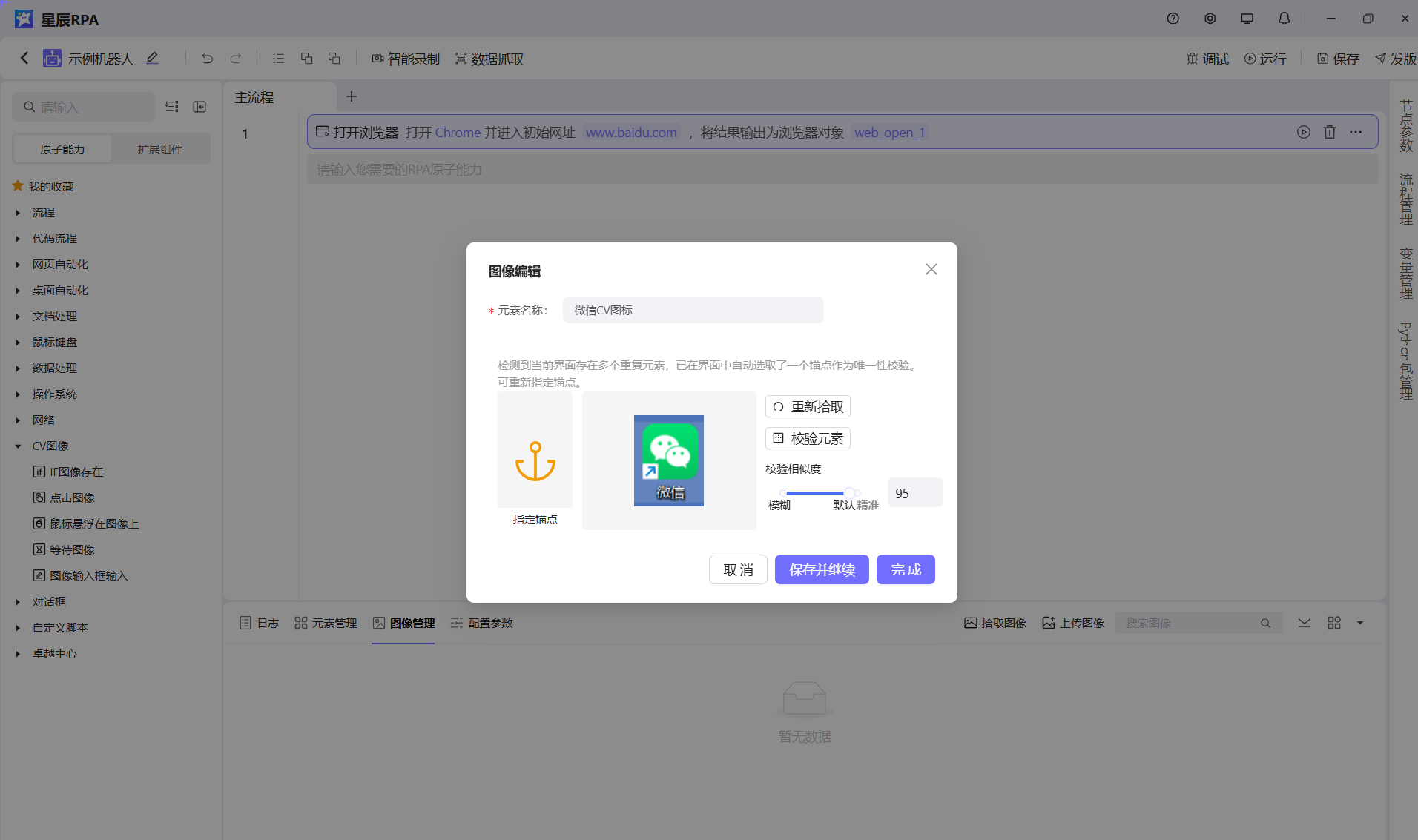
方法三:使用CV拾取兜底
当元素无法通过常规方式(DOM、UIA等)稳定识别时,可以使用CV(计算机视觉)拾取作为兜底方案。
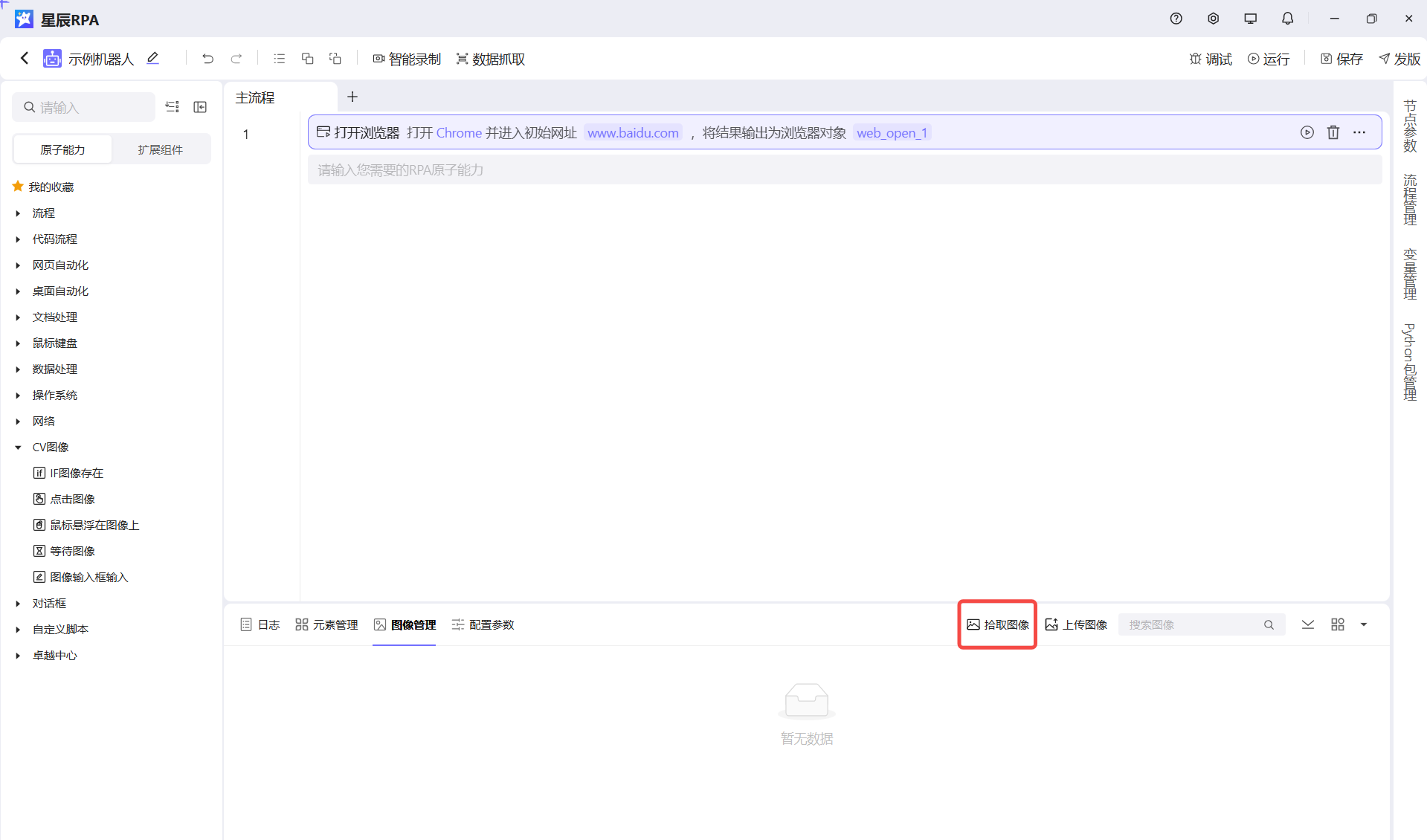
- 不过CV的局限性也很多,比如画面不能变动,只能获取到位置属性,不能获取内容等弊端,配合快捷键操作也不是一种比较全面的兜底方案
场景 2:动态修改拾取数据
当你足够熟悉拾取的Xpath,想通过代码动态调整里面的参数,可以使用这种方式
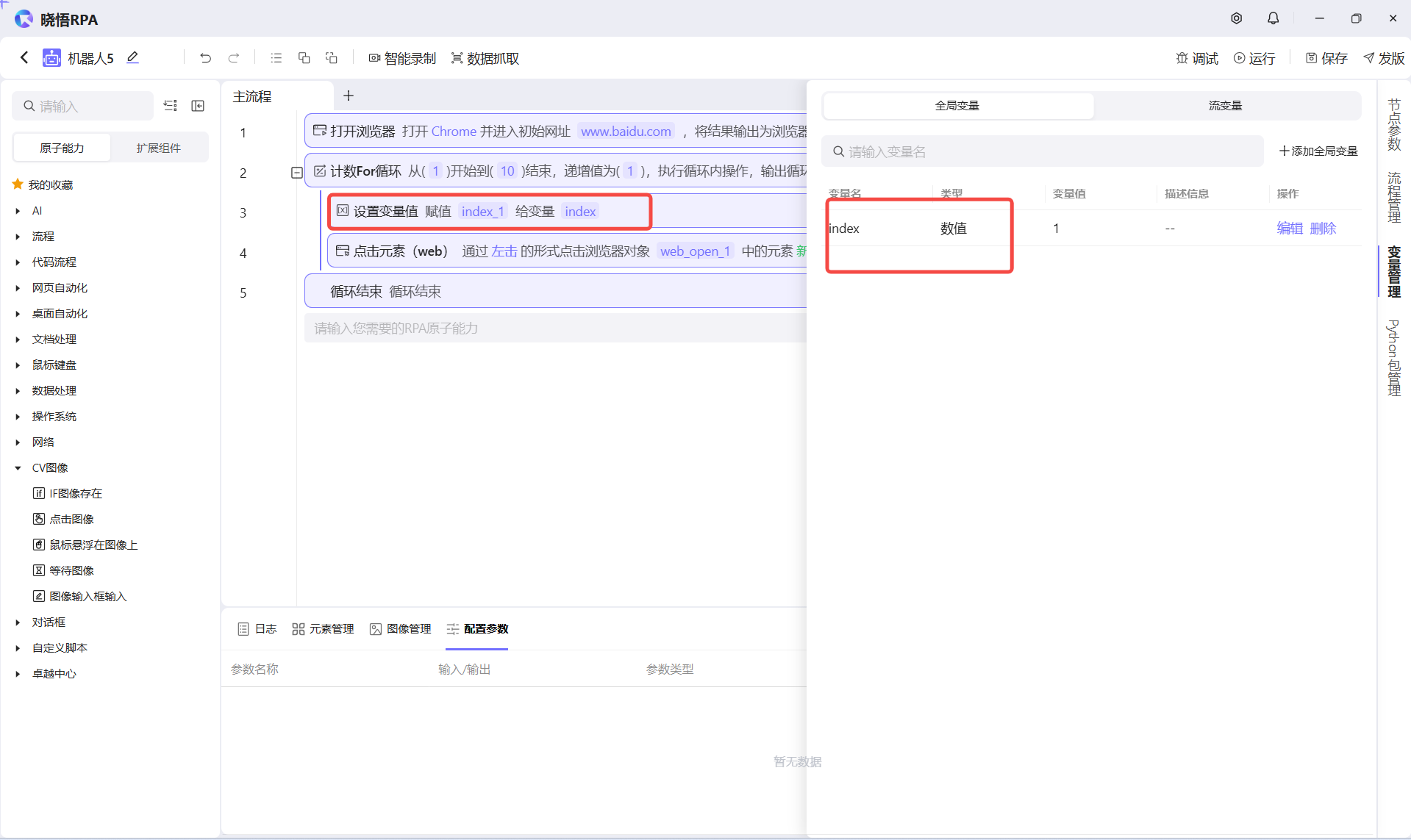
由于修改元素只能通过全局变量,我上面准备了一个案例,通过设置变量值,将流程里面的数据设置到全局变量里面,这样点击元素的元素就是生成的了
常见问题及解决方法
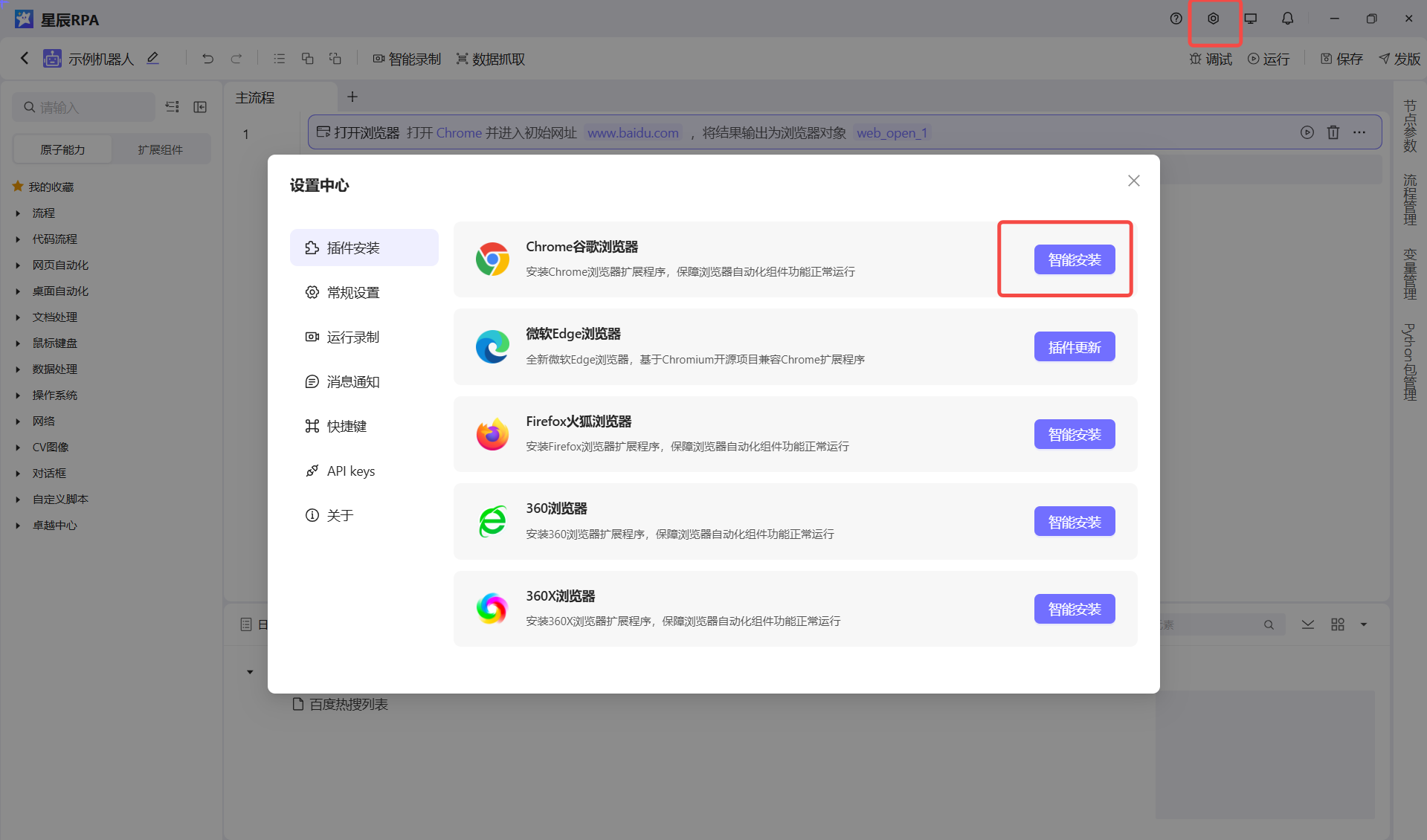
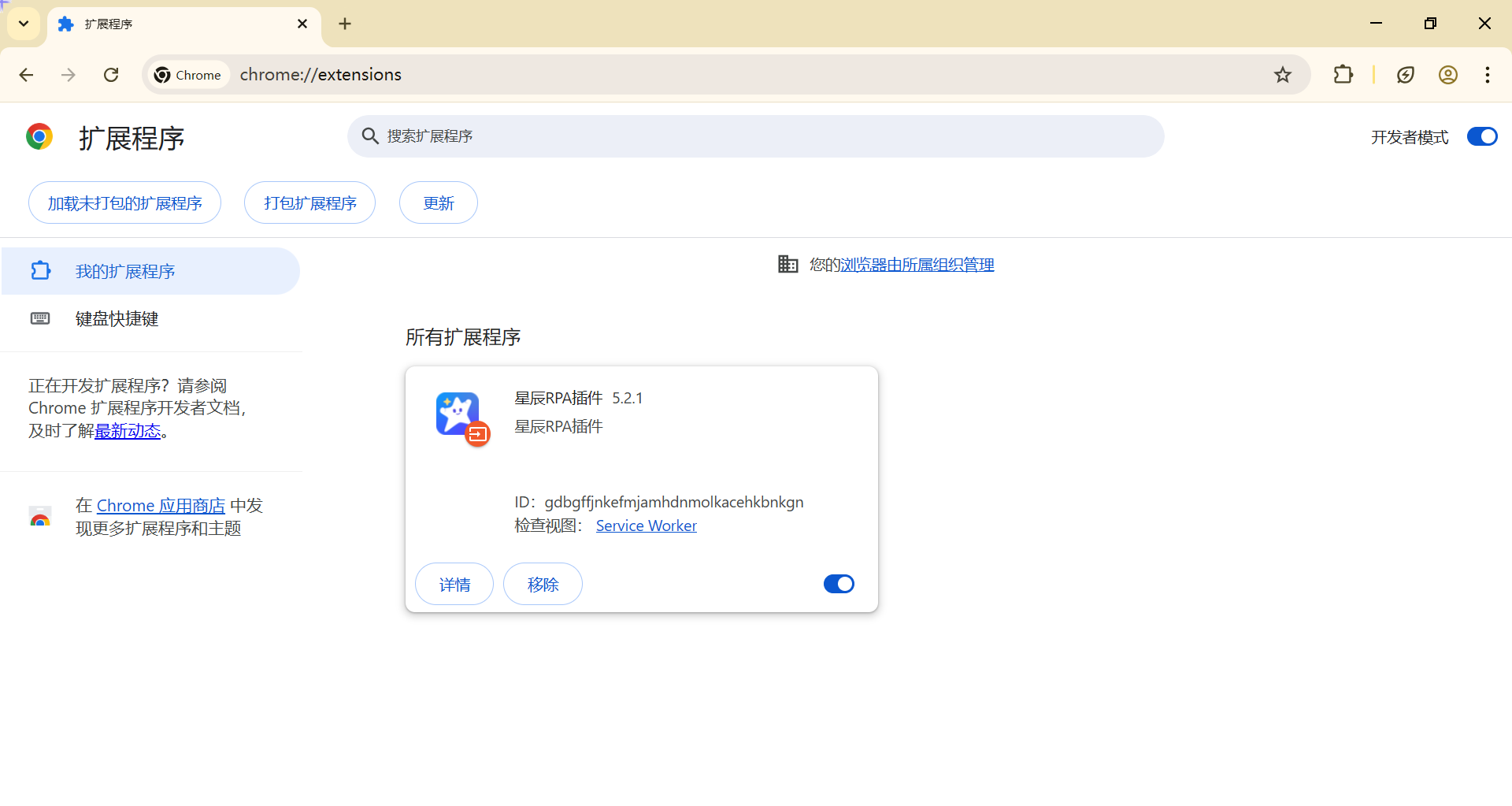
问题 1:Web 元素无法拾取
症状:浏览器中的元素无法拾取
可能原因:
- 浏览器扩展未安装或未启用
- 浏览器版本不兼容
问题 2:桌面 元素无法拾取
症状:桌面的元素无法拾取
可能原因:
- 第三方软件强制屏蔽探测,这个无法解决
- 拾取技术没有对软件适配,可以提供给我们做适配